| Accumulate Records | Combines measurements from an input table for all image frames. Best used on data sets like z stacks that have multiple points data is measured from. Can choose to accumulate data for timelapse only or for all loops. |
| Append Columns | Takes any number of tables with the same number of entries and condenses them into additional columns of a single table. When using measurements from the same binary layer, you can also use ctrl + click to highlight the measurements and group them. However, this operation is useful for concatenating data from the same objects of interest across different binary layers. |
| Calculated Column | Takes a table as input and adds an additional column that is the output of a specified mathematical operation (ex. taking an area measurement and dividing it by 2). |
| Duplicate Column | From an input table, adds a copy of the specified column. Can choose name of copy and units. |
| Modify Columns | Takes a table as input and allows each column to be renamed or expressed in a different format (ex. converting large pixel areas to scientific notation). Can also specify decimal precision of data and move columns relative to each other. These operations can also be performed by clicking the gear symbol directly from the table. |
| Scale Column Data | Changes every value in a specified column of a table by a chosen offset and gain. Offset 0 and gain 1 cause no change to the values. |
| Aggregate Rows | Collapses each column in a table into a single row based on parameters that can be selected for each (count, mean, a certain percentile, sum, etc.). |
| Filter Groups | Removes groups of entries in a table that do not meet the specified conditions. Options for analysis calculate the same values as Aggregate Rows. Best used after modifying groups with Group Records/Ungroup Records. |
| Group Records | Classifies objects in a table based on the selected column(s). Objects are in a single group by default. Grouping by ID will make each object its own group. |
| Ungroup Records | Undoes the effect of Group Records. May be useful to use it after Filter Groups. |
| Filter Records | Removes table entries that do not meet the specified criteria. Can choose column, comparator, and value. Good for removing objects that are too small, not circular enough, etc. |
| Select First & Last | Removes all entries except for the first and last in a table. |
| Select Records | Selects records in a table starting from the specified row for the specified count. Ex. first row=2 and count=4 would remove all rows from the table except for 2, 3, 4, and 5. |
| Select Top | Selects certain rows of a table. Name is misleading, can choose column to filter by, how to choose what rows are included, and the number of rows to include. For example, you can select the 5 objects with the largest area by selecting FillArea for the column, sorting by Biggest, and setting count to 5. |
| Sort Records | Sorts a table’s rows using the specified column and order. |
| Pivot Table | Switches selected columns to rows. Several options for customizing how the table is modified. |
| Append Records | Takes any number of tables that are different measurements of the same objects and combines them like Append Columns. However, the formatting is different, and each input table is given its own row.  |
| Compact Columns | Combines all columns with the same name into 1 column. Useful if you have combined tables of similar measurements. |
| Copy Column ID | Modifies column IDs from input tables so they match better and will merge when combining tables. Need to select which columns will be affected and what column to get ID from. |
| Format Time | Converts a column containing time data into another format. Need to specify the name of the new column and the column to pull data from, and can choose to reformat time as milliseconds, seconds, minutes, or hours. |
| Join Records | Combines 2 tables with different numbers of entries (ex. cell data and nuclei data). Less useful than it sounds, the output of the cells/nuclei example using any join type had a number of rows equal to (rows A) * (rows B) and had a repeat of cell properties for each nucleus object. |
| New Column ID | Makes specified columns considered to be unique so they will not join with a column of the same name when tables are combined. |
| Shift Records | Manipulates position of data in columns. Can choose how many rows down to shift data and how vacated rows are filled (leave them empty, fill with the original values, or wrap around from the bottom of the table). |
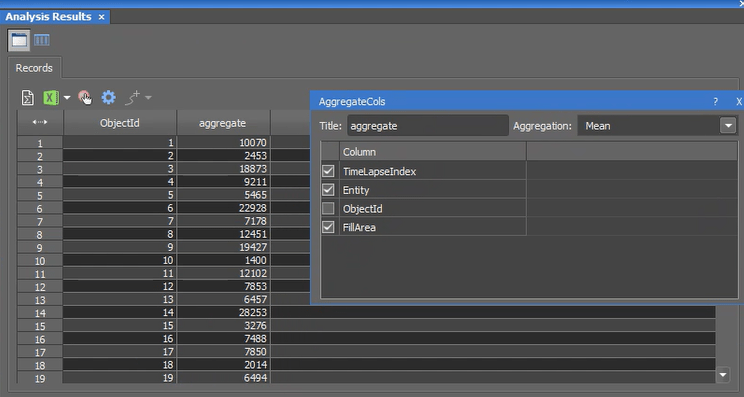
| Aggregate Columns | Combines data from each row of the selected columns based on a chosen method.  |
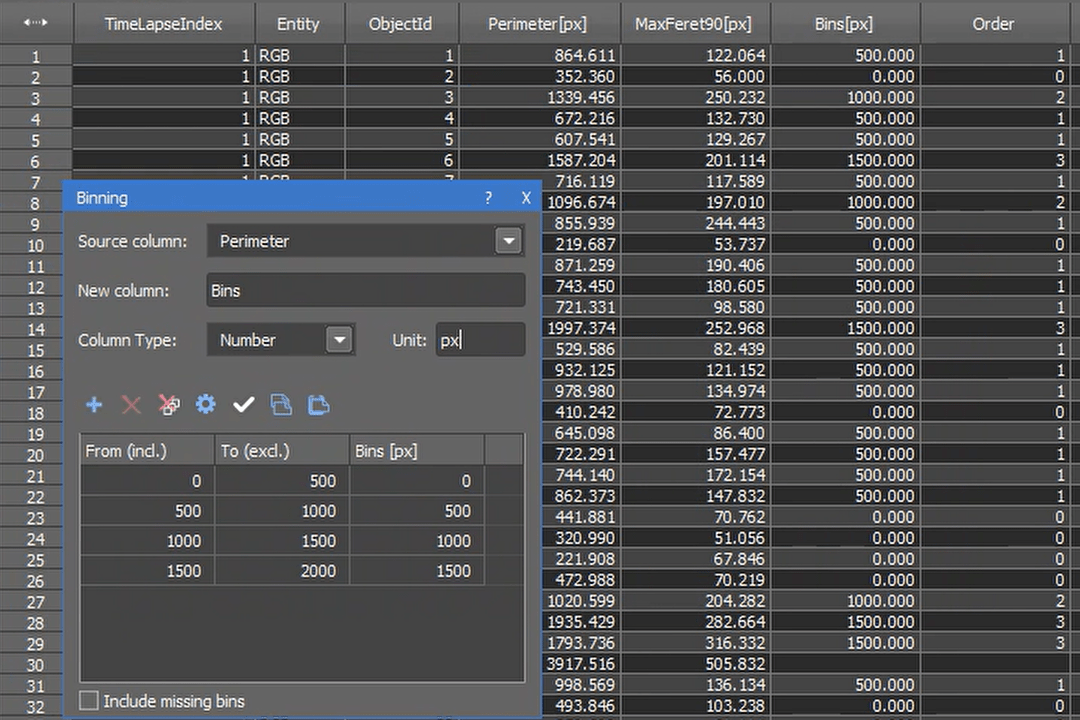
| Binning | Creates a column to bin rows of a selected source column into groups. Can choose the type of data in the bin column to be numbers or strings and units of the column. Need to use the gear to set up bins, options include logarithmic or linear. Example shown here sorts objects into 4 bins based on perimeter (objects with perimeter > 2000 are not put in a bin).  |
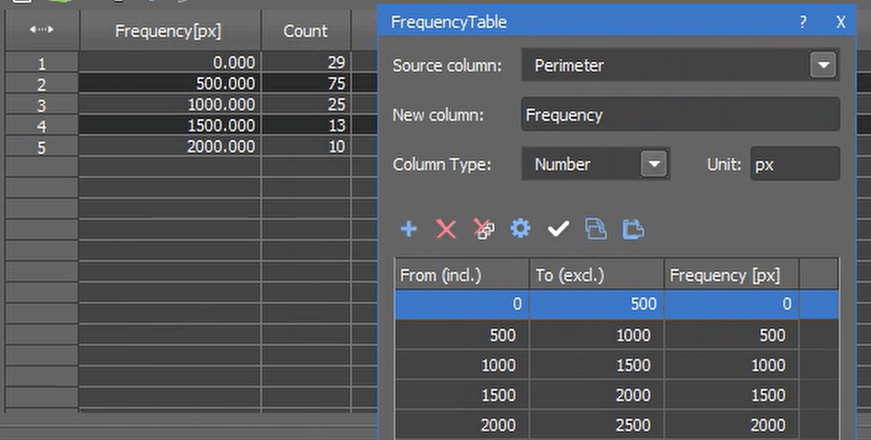
| Frequency Table | Works like Binning but collapses table into bins and the number of objects in each.  |
| Statistics | Gives selected statistics for each column of a table. Options include mean, percentiles, standard deviation, minimum and maximum, number of distinct values, etc. |
| F-test | Performs an F-test on selected columns of 2 tables, which is a statistical test that checks if the variances of 2 populations are equal. Can choose hypothesized ratio of variances, confidence level, and alternative hypothesis as one or two sided. Output displays a lot of values, the most important are Var1(A) and Var1(B), which are the variances, Ratio (A/B), the ratio of the variances, H0Rejected, which is 0 if false and 1 if true, and p-value. |
| t-test 1-sample | A statistical test that performs a 1-sample t-test on a specified data column of a table. The 1-sample t-test determines if the population mean is equal to a hypothesized value. Can also specify confidence level of test and whether test is 1-sided or 2-sided. Output will display sample mean, confidence interval, sample standard deviation, whether H0 is rejected or not, and p-value. |
| t-test 2-sample Paired | A statistical test that determines if paired data columns from a table have a hypothesized difference in means. Can select which columns to test, hypothesized difference, confidence level, and whether test is 1 or 2-sided. |
| t-test 2-sample Unpaired | A statistical test that determines if samples from 2 tables have a hypothesized difference in mean. Can choose columns, hypothesized difference, confidence level to use for test, whether to assume the variances are equal, and if the test is 1 or 2-sided. |
| ANOVA One-way | Analysis of variance. Input table must be sorted into groups of more than 1 object each to use ANOVA because degrees of freedom are used in the calculation. Need to select data to perform test on and confidence level. |
| Generate Distribution | Generates an independent table of a specified statistical distribution. Node does not take any inputs. Can choose between t-distribution and f-distribution and specify parameters that define them, as well as left and right endpoints and step size. Also includes a box to check to switch between probability density function and cumulative distribution function. |
| Addition | Uses vector addition to calculate the sum of specified positions from a table. Can choose which columns are added together, but only takes 1 table as input, so appending columns beforehand is useful. |
| Difference (vector) | Performs vector subtraction on specified columns of an input table. |
| Distance | Calculates the magnitude of the distance vector between two points specified by each row of the selected columns. |
| Vector Length | Calculates the magnitude of a vector defined by the specified columns of the input table. |
| Vector Orientation | Calculates direction of a vector defined by the specified columns of the input table in degrees from positive X-axis. |
| Find Local Extrema | Finds local minima and maxima in the specified column of a table and displays them in a new column. |
| Rolling Average | Calculates a rolling average of the specified column from the input table. Can choose length of window to calculate the average from (which is the number of entries before and after the center, so using a window of 3 would take an average of 7 entries: 3 before, the value itself, and 3 after). |
| Rolling Median | Calculates a rolling median of a column, using the same window rules as Rolling Average. |
| Rolling Minimum | Calculates a rolling minimum of a column, using the same window rules as Rolling Average. |
| Rolling Maximum | Calculates a rolling maximum of a column, using the same window rules as Rolling Average. |
| Curve Fitting | Given specified dependent and independent variables, creates a column of curve values for the specified curve type using least squares. Can choose from linear, quadratic, polynomial of specified degree, exponential, etc. for curves. |
| Curve Fitting Params | Like Curve Fitting but displays curve R2, coefficients, and equation in a row. |
| Dose Response | Calculates points of a dose-response logistic curve fit to the specified columns representing dose and response. Can choose 4-parameter or 5-parameter curve and assign values if required. |
| Dose Response Params | Like Dose Response but displays curve parameters in a row as opposed to points. |
| Gauss Mixture | A curve fitting option for picking out multiple peaks from data. Need to specify data columns and number of peaks to find. Output shows values of the fit Gaussian functions, with one column for each peak found. |
| Gauss Mixture Params | Like Gauss Mixture but outputs parameters of each peak. Can choose to display output as one equation containing all peaks or as one row describing each peak. |
| DBSCAN | An algorithm for classifying groups of objects into clusters. Need to specify X and Y position columns, the maximum distance an object can be from another and still be considered a neighbor, and the minimum number of neighbors an object needs to be considered part of a cluster core. Output column will show cluster ID of each object. |
| |
| Grid Points | If table has gridline points, adds coordinates of missing points to table. |
| Parse Well Name | Using an input column that contains combined well row and column data, splits it into separate columns for well rows and well columns. |
| TMA Dearraying | Indexes a tissue microarray. If Skip Gaps is turned on, missing positions will not be skipped in numbering, otherwise index number will correspond to grid position. |
| Values Run | Looks for values shared between rows of a selected Column with different Index Column IDs. Values are shared if the output column contains the same ID in different rows. |
| Difference | Adds a column to a table that displays the difference between subsequent rows of the selected column. |
| Integrate | Adds a column to a table that displays the sum of all previous rows of the specified column. A constant can also be added to each entry of the sum column. |
| Position Difference | Adds columns that define components of the vector difference between consecutive points determined by the selected columns. |
| Position Integrate | Adds columns that show components of the vector sum of all previous rows of the specified position columns. |
| High Pass Filter | A high pass filter that can be applied to a column. Can select column, how filtered column loops, and alpha value (which determines filter strength). Best used on time values, did not produce a meaningful result when used on an area measurement. |
| Low Pass Filter | A low pass filter that can be applied to a column. Can select column, how the new column loops, and alpha value (filter parameters, different calculation than High Pass Filter). When used on a column of area measurements, it removed unusually high values and increased the value of smaller measurements. |
| Sequence | Adds a column that contains a sequence of integers. Can select start value and step size. |
| JS Create Column/JS Create Table/JS Scalar Expression | These options open a JavaScript dialog for coding custom table operations. Create Column fills a new column with custom coded values, Create Table makes a new table specified by a coded array, and Scalar Expression evaluates a coded expression. |